
When to go deep. Technical expertise. A bit about open source. Becoming the cognitive referent.
Techwolf, open source and talking about the recipe. Hungry like the Techwolf.
I have written how often founders get overly enamoured with talking about their technical wizardry (the recipe) to anyone who can’t escape the room without coherently first explaining the menu (why). This can lead extreme boredom and a lack of sales. See post below for more.
However, I’m not suggesting that you never go deep on the technology, just that you do it at the right time, and with the right audience. If your technology is a differentiator, then you need to get that message across. Sometimes that means going deep.
A few days ago I read a post on Linkedin by Wade Arnold, the CEO of Moov, about a talk that Anshu Sharma, the CEO of Skyflow, gave at a conference. Here’s an excerpt.
Instead of a sales pitch, he went deep into how encryption and security actually work. Four layers deeper than anyone expected.
I learned something important that day, too:
When you're building something deeply technical, your expertise is your most powerful marketing tool. Demonstrating profound knowledge builds immediate credibility. The right audience recognizes real depth instantly.
Skyflow is probably worth a billion dollars now. All because Anshu deliberately chooses education over promotion.
For technical founders in B2B, especially in developer-first industries, our deepest technical insights are our most effective go-to-market strategy.
The Techwolf example
A couple of months ago I was in Ghent, I saw Jeroen, a co-founder of Techwolf (one of our portfolio companies) speak to a packed room of AI experts and software developers. For a chunk of that talk he went technical, people leaned forward and listened. He held the room in his hand. He explained how their latest skills matching models performed, and discussed why they had open-sourced their research.
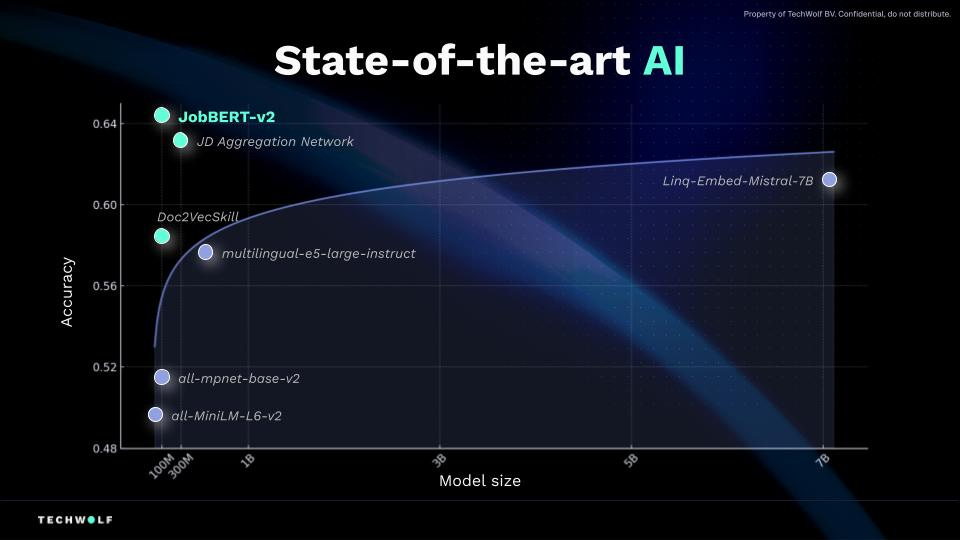
The Chief Research Scientist at Techwolf has also posted about their open source commitments.
Techwolf has since released V3 of JobBERT.
Here’s an academic paper about it. https://arxiv.org/abs/2507.21609
We introduce JobBERT-V3, a contrastive learning-based model for cross-lingual job title matching. Building on the state-of-the-art monolingual JobBERT-V2, our approach extends support to English, German, Spanish, and Chinese by leveraging synthetic translations and a balanced multilingual dataset of over 21 million job titles. The model retains the efficiency-focused architecture of its predecessor while enabling robust alignment across languages without requiring task-specific supervision. Extensive evaluations on the TalentCLEF 2025 benchmark demonstrate that JobBERT-V3 outperforms strong multilingual baselines and achieves consistent performance across both monolingual and cross-lingual settings. While not the primary focus, we also show that the model can be effectively used to rank relevant skills for a given job title, demonstrating its broader applicability in multilingual labor market intelligence. The model is publicly available:
And a recent paper about extracting skills data from job adverts. https://arxiv.org/abs/2505.24640
Labor market analysis relies on extracting insights from job advertisements, which provide valuable yet unstructured information on job titles and corresponding skill requirements. While state-of-the-art methods for skill extraction achieve strong performance, they depend on large language models (LLMs), which are computationally expensive and slow. In this paper, we propose \textbf{ConTeXT-match}, a novel contrastive learning approach with token-level attention that is well-suited for the extreme multi-label classification task of skill classification. \textbf{ConTeXT-match} significantly improves skill extraction efficiency and performance, achieving state-of-the-art results with a lightweight bi-encoder model. To support robust evaluation, we introduce \textbf{Skill-XL}, a new benchmark with exhaustive, sentence-level skill annotations that explicitly address the redundancy in the large label space. Finally, we present \textbf{JobBERT V2}, an improved job title normalization model that leverages extracted skills to produce high-quality job title representations. Experiments demonstrate that our models are efficient, accurate, and scalable, making them ideal for large-scale, real-time labor market analysis.
Check out the engineering blog.
Why does this matter?
Using AI in the workplace, for instance to support workforce planning, essentially means that you are impacting people’s careers, financial well-being (for good or bad). It’s quite a responsibility. It’s why we have the EU AI Act, but just because you use AI, doesn’t mean that existing labour laws go by the wayside. Genuine AI adoption in the enterprise is going to require the trust of both the economic buyer and the employees.
Putting it bluntly, does the product actually work?
By sharing precisely how they have built the underlying AI engine, and how they have sourced their data, Techwolf is setting a benchmark for transparency and safety. It’s a fundamental element of Responsible AI. By putting their models up for peer review, they help drive broader industry progress too.
Downloads of models have now crossed 250k, and Techwolf has already seen other software companies adopt them. For instance, one of our other portfolio companies, Compa is using the models. Compa does a brilliant job of building a community of experts. They also go deep into the mechanics of compensation. Learn more about that here.
Keeping everything secret is one way to work, but being open enables Techwolf to establish deep credibility. As you dig into this you’ll see there is a lot more to this than just chucking it in an LLM.
I’m no expert in open source, I’ll leave that to Dirk and James etc. Open source changed how databases and programming languages are developed, and the debate between open and proprietary models rages on in LLM land. We will be hearing more about it.
As the value in enterprise software shifts more an more towards AI, buyers will need to learn to ask a whole set of new questions. Techwolf are in the powerful position to meet with the chief AI officer or data scientist of any fortune 1000 company, and explain precisely how their product works. The deeper it goes, the better they do.
Techwolf is well on the way to being the cognitive referent for skills and skills inference. You can’t really understand the impact of AI on your organization if you don’t understand both AI and your organization.
Playing in ecosystems
Techwolf works best as part of the broader worktech ecosystems. It integrates with SAP, Workday, ServiceNow and more commercially and technically.
The engineering team recently won the devcon hackathon at Workday. Showcasing those deep AI technical chops in 24 hours.

Techwolf will be at Workday Rising. Andreas, the CEO is speaking, and the other founders will be there too. Head to their event if you are. They will also be at Unleash, HR Tech and more this autumn. If you get the chance, go deep….
As I usually do, I’ll end with a tune. Duran Duran are playing at Workday Rising. While I don’t do vendors events these days, this does give me a bit of FOMO.
You guessed it. Hungry like the (tech)wolf.
Love that you ended with the importance of the ecosystem. Techwolf has pulled all the right levers and has positioned themselves for the growth phase. Great article Thomas!
Really interesting take! But sometimes I worry that all this talk about ‘transparent’ AI and open tech is just clever branding. How can we tell when a company is genuinely open, versus just spinning a good story to win trust?